
Wu, Hanlin, Lin, Pengfei, Javanmardi, Ehsan, Bao, Naren, Qian, Bo, Si, Hao, Tsukada, Manabu, "A Synthetic Benchmark for Collaborative 3D Semantic Occupancy Prediction in V2X-Enabled Autonomous Driving ", In: IEEE International Conference on Robotics & Automation (ICRA 2026), Vienna, Austria, 2026.Proceedings Article | Abstract | Links | BibTeX
@inproceedings{Wu2026,
title = {A Synthetic Benchmark for Collaborative 3D Semantic Occupancy Prediction in V2X-Enabled Autonomous Driving },
author = {Hanlin Wu and Pengfei Lin and Ehsan Javanmardi and Naren Bao and Bo Qian and Hao Si and Manabu Tsukada},
url = {https://arxiv.org/abs/2506.17004
https://github.com/tlab-wide/Co3SOP},
year = {2026},
date = {2026-06-01},
urldate = {2026-06-01},
booktitle = {IEEE International Conference on Robotics & Automation (ICRA 2026)},
address = {Vienna, Austria},
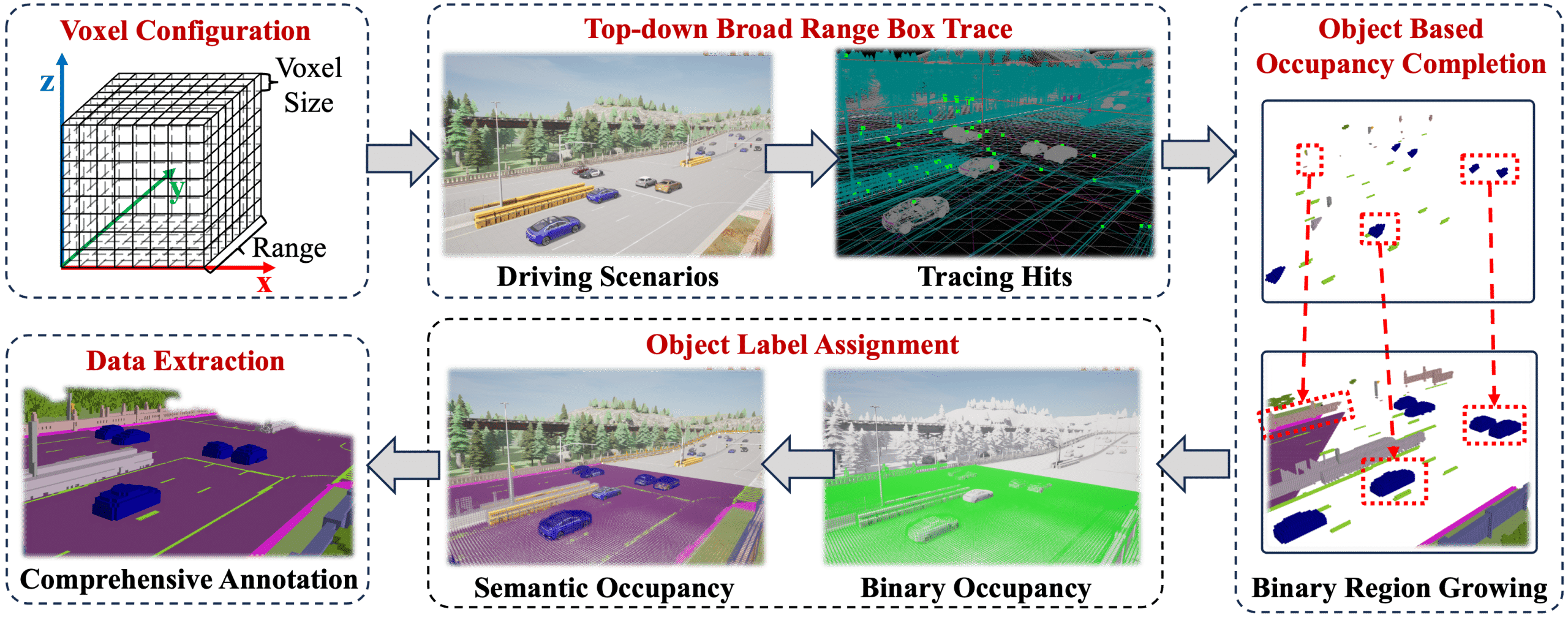
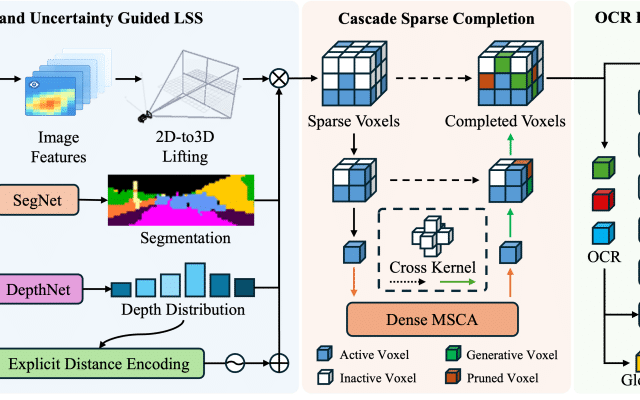
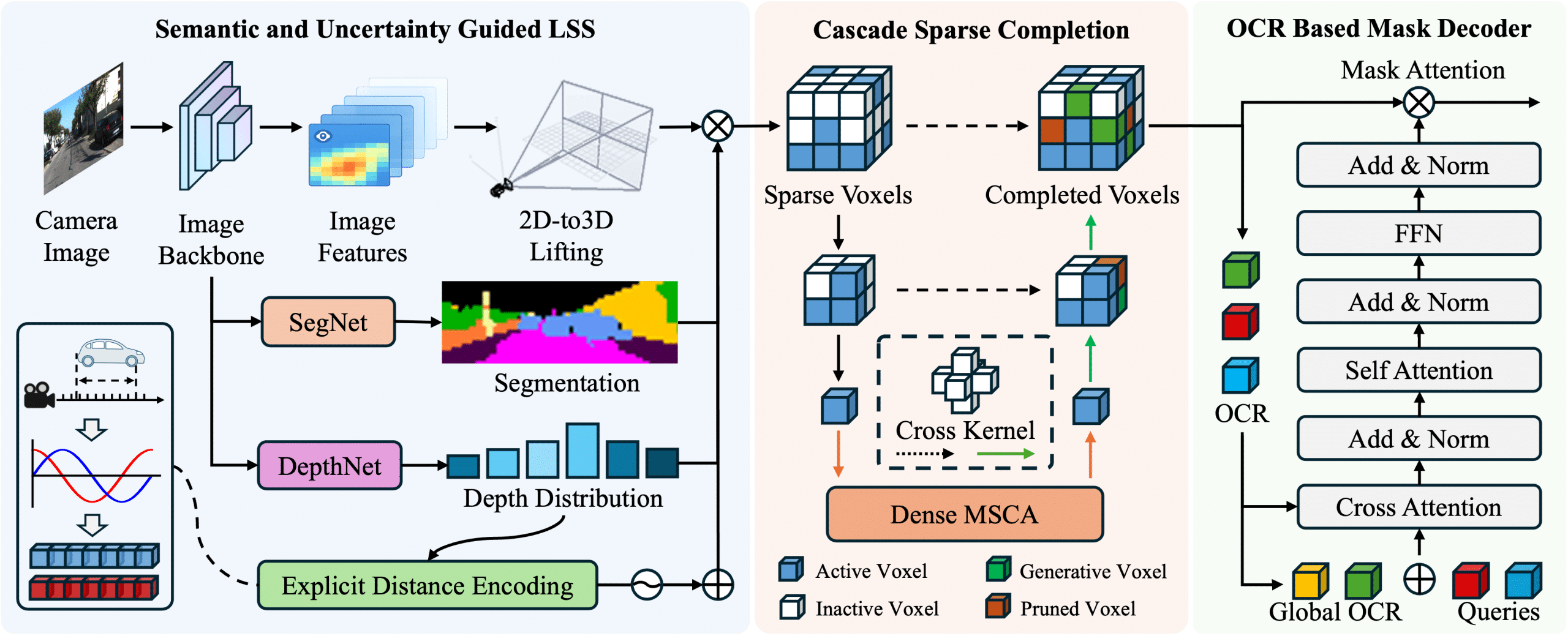
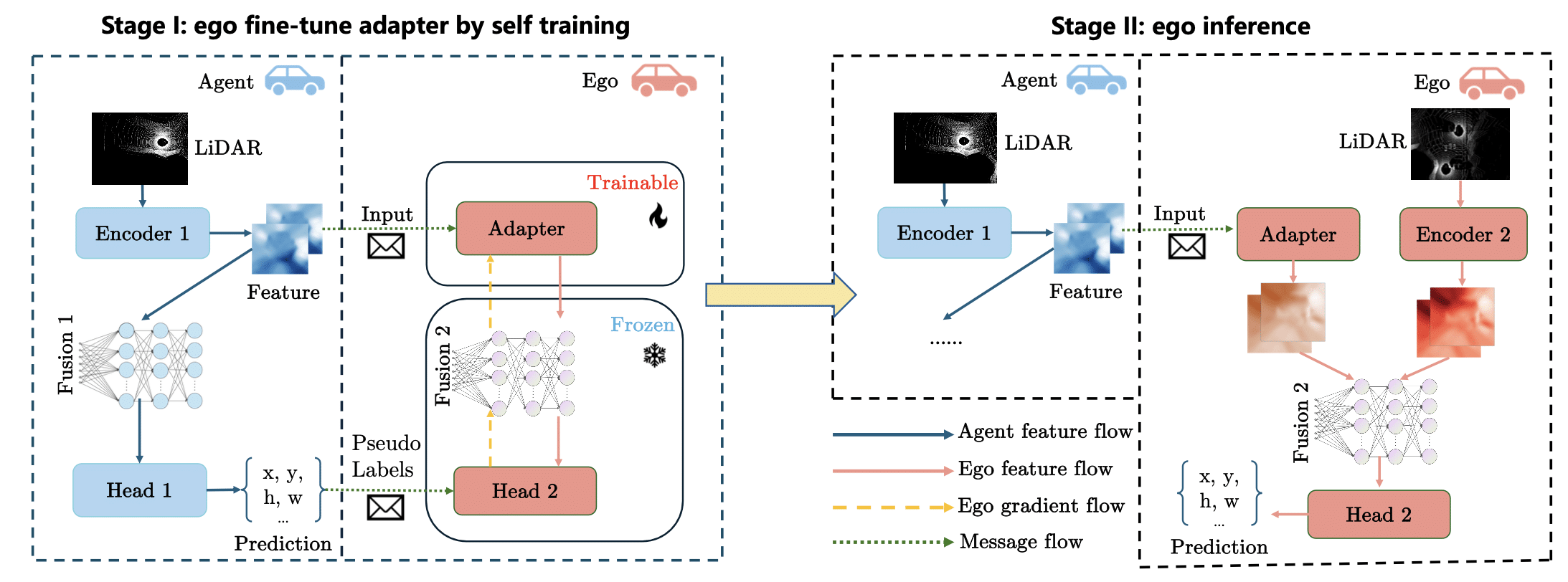
abstract = {3D semantic occupancy prediction is an emerging perception paradigm in autonomous driving, providing a voxel-level representation of both geometric details and semantic categories. However, its effectiveness is inherently constrained in single-vehicle setups by occlusions, restricted sensor range, and narrow viewpoints. To address these limitations, collaborative perception enables the exchange of complementary information, thereby enhancing
the completeness and accuracy of predictions. Despite its potential, research on collaborative 3D semantic occupancy prediction is hindered by the lack of dedicated datasets. To bridge this gap, we design a high-resolution semantic voxel sensor in CARLA to produce dense and comprehensive annotations. We further develop a baseline model that performs inter-agent feature fusion via spatial alignment and attention aggregation. In addition, we establish
benchmarks with varying prediction ranges designed to systematically assess the impact of spatial extent on collaborative prediction. Experimental results demonstrate the superior performance of our baseline, with increasing gains observed as range expands. },
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
3D semantic occupancy prediction is an emerging perception paradigm in autonomous driving, providing a voxel-level representation of both geometric details and semantic categories. However, its effectiveness is inherently constrained in single-vehicle setups by occlusions, restricted sensor range, and narrow viewpoints. To address these limitations, collaborative perception enables the exchange of complementary information, thereby enhancing
the completeness and accuracy of predictions. Despite its potential, research on collaborative 3D semantic occupancy prediction is hindered by the lack of dedicated datasets. To bridge this gap, we design a high-resolution semantic voxel sensor in CARLA to produce dense and comprehensive annotations. We further develop a baseline model that performs inter-agent feature fusion via spatial alignment and attention aggregation. In addition, we establish
benchmarks with varying prediction ranges designed to systematically assess the impact of spatial extent on collaborative prediction. Experimental results demonstrate the superior performance of our baseline, with increasing gains observed as range expands.
the completeness and accuracy of predictions. Despite its potential, research on collaborative 3D semantic occupancy prediction is hindered by the lack of dedicated datasets. To bridge this gap, we design a high-resolution semantic voxel sensor in CARLA to produce dense and comprehensive annotations. We further develop a baseline model that performs inter-agent feature fusion via spatial alignment and attention aggregation. In addition, we establish
benchmarks with varying prediction ranges designed to systematically assess the impact of spatial extent on collaborative prediction. Experimental results demonstrate the superior performance of our baseline, with increasing gains observed as range expands.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}