塚田研究室は、東京大学大学院 情報理工学系研究科 創造情報学専攻の研究室です。コンピュータネットワークとサイバーフィジカルシステムを基盤とし、協調型自動運転、混合現実、次世代通信、没入型メディアなど幅広い研究に取り組んでいます。
0%

塚田研究室は、東京大学大学院 情報理工学系研究科 創造情報学専攻の研究室です。コンピュータネットワークとサイバーフィジカルシステムを基盤とし、協調型自動運転、混合現実、次世代通信、没入型メディアなど幅広い研究に取り組んでいます。
IEEE INFOCOM 2026 🎊
Hilton Tokyo / ~900 researchers / first time in Japan in 29 years.
Honored to serve as Local Arrangements Chair.
🏆 Congrats to Quanxi Zhou — Best Paper Runner-up Award at the DOICT-IndSoc Workshop!
Thanks to our amazing student volunteers 🙏
#INFOCOM2026 #IEEE #UTokyo #TLab #Networking
5月 20

Welcome pizza party 🍕
Excited to start a new semester together! #utokyo #東京大学
5月 11
🎉 Presented at ACM CHI 2026 in Barcelona (Apr 13–17)!
Our paper “Don’t Worry, Just Follow Me: Prototyping and In-the-Wild Evaluation of Smart Pole Interaction Unit with Mobility” proposes an infrastructure-based eHMI that supports smoother communication between pedestrians and autonomous vehicles — and received an Honorable Mention Award 🏆
Congrats to the team!
#CHI2026 #HCI #eHMI #UTokyo #TLab
4月 20
Invited talk at the Symposium on Human-AI Interaction at National Chengchi University (NCCU), Taipei. Presented our research on communication infrastructure connecting diverse mobile devices and humans, including two CHI 2026 Honourable Mention papers on Smart Pole Interaction Units and VLM Personas for embodied HCI studies. Thank you Prof. Shih-Yi Chien for the invitation!
3月 31
Congratulations to our graduates! 🎓 Wishing you all the best on your next chapter. #utokyo #東京大学
3月 30
Farewell party #utokyo #東京大学
3月 27
Attended the retirement lecture of Prof. Yusheng Ji at NII. It has been a privilege to collaborate with her on the JST ASPIRE project. Wishing her all the best in this new chapter!
3月 24
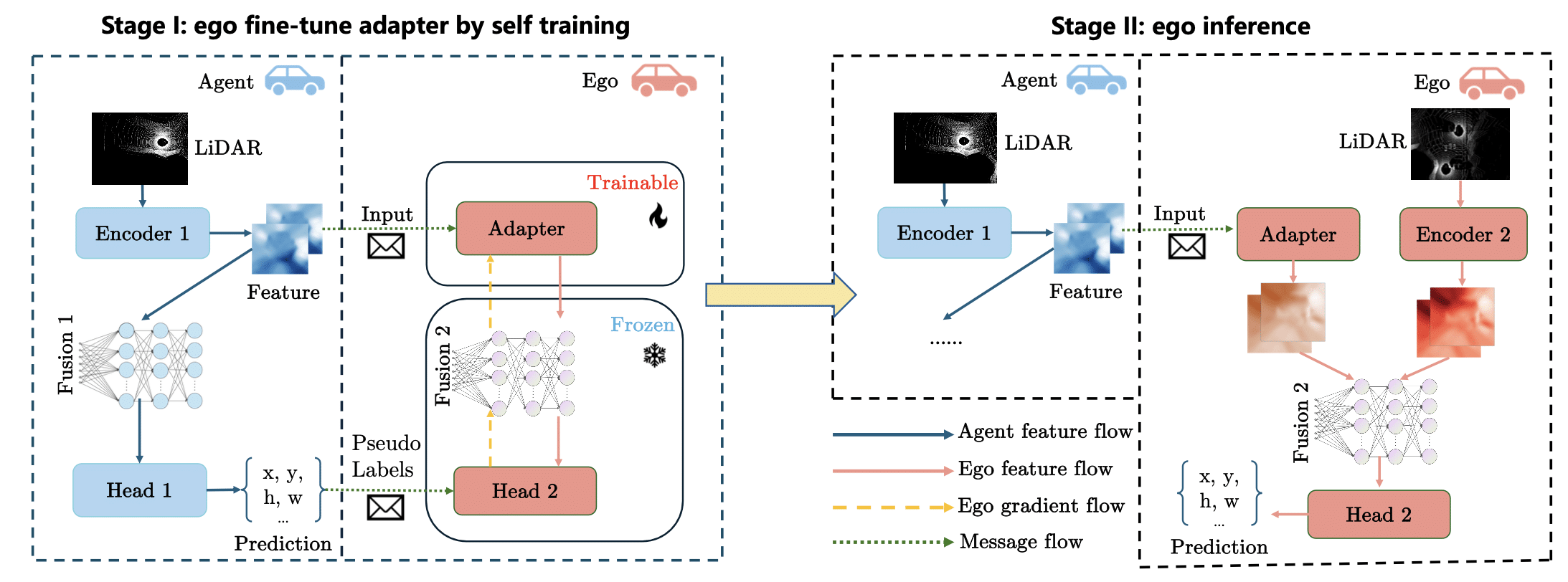
Welcomed Verena and Rutuja from TUM to discuss autonomous driving research — bridging human-centered design and cooperative vehicle systems.
#utokyo #東京大学
3月 23
JST CREST Internet of Realities Symposium #utokyo #東京大学
3月 20
Great meeting with Dr. Rui Shi from Beijing University of Technology—excited to exchange ideas on explainable autonomous driving! #utokyo
2月 4









IEEE INFOCOM 2026 🎊
Hilton Tokyo / ~900 researchers / first time in Japan in 29 years.
Honored to serve as Local Arrangements Chair.
🏆 Congrats to Quanxi Zhou — Best Paper Runner-up Award at the DOICT-IndSoc Workshop!
Thanks to our amazing student volunteers 🙏
#INFOCOM2026 #IEEE #UTokyo #TLab #Networking
5月 20
Welcome pizza party 🍕
Excited to start a new semester together! #utokyo #東京大学
5月 11
🎉 Presented at ACM CHI 2026 in Barcelona (Apr 13–17)!
Our paper “Don’t Worry, Just Follow Me: Prototyping and In-the-Wild Evaluation of Smart Pole Interaction Unit with Mobility” proposes an infrastructure-based eHMI that supports smoother communication between pedestrians and autonomous vehicles — and received an Honorable Mention Award 🏆
Congrats to the team!
#CHI2026 #HCI #eHMI #UTokyo #TLab
4月 20
Invited talk at the Symposium on Human-AI Interaction at National Chengchi University (NCCU), Taipei. Presented our research on communication infrastructure connecting diverse mobile devices and humans, including two CHI 2026 Honourable Mention papers on Smart Pole Interaction Units and VLM Personas for embodied HCI studies. Thank you Prof. Shih-Yi Chien for the invitation!
3月 31
Congratulations to our graduates! 🎓 Wishing you all the best on your next chapter. #utokyo #東京大学
3月 30
Farewell party #utokyo #東京大学
3月 27
Attended the retirement lecture of Prof. Yusheng Ji at NII. It has been a privilege to collaborate with her on the JST ASPIRE project. Wishing her all the best in this new chapter!
3月 24
Welcomed Verena and Rutuja from TUM to discuss autonomous driving research — bridging human-centered design and cooperative vehicle systems.
#utokyo #東京大学
3月 23
JST CREST Internet of Realities Symposium #utokyo #東京大学
3月 20
Great meeting with Dr. Rui Shi from Beijing University of Technology—excited to exchange ideas on explainable autonomous driving! #utokyo
2月 4












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}