

Trumpp, Raphael, Javanmardi, Ehsan, Nakazato, Jin, Tsukada, Manabu, Caccamo, Marco, "RaceMOP: Mapless Online Path Planning for Multi-Agent Autonomous Racing using Residual Policy Learning", In: The 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2024), Abu Dhabi ,UAE, 2024.Proceedings Article | Abstract | Links | BibTeX
@inproceedings{Trumpp2024,
title = {RaceMOP: Mapless Online Path Planning for Multi-Agent Autonomous Racing using Residual Policy Learning},
author = {Raphael Trumpp and Ehsan Javanmardi and Jin Nakazato and Manabu Tsukada and Marco Caccamo},
url = {http://github.com/raphajaner/racemop},
doi = {10.1109/IROS58592.2024.10801657},
year = {2024},
date = {2024-09-14},
urldate = {2024-09-14},
booktitle = {The 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2024)},
address = {Abu Dhabi ,UAE},
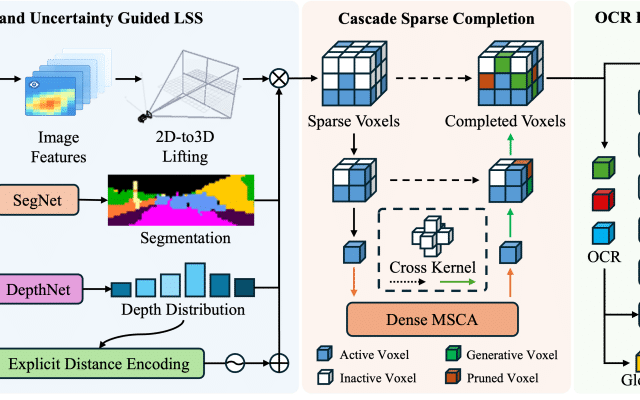
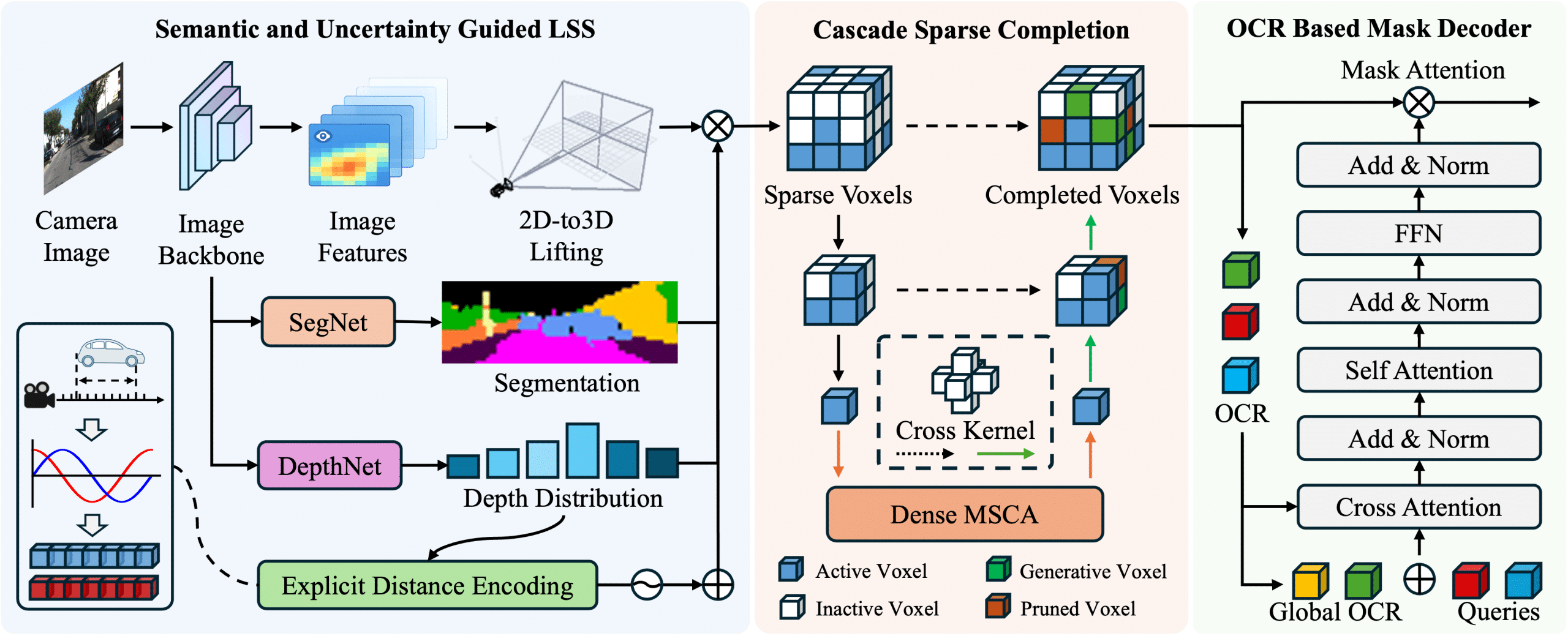
abstract = {The interactive decision-making in multi-agent autonomous racing offers insights valuable beyond the domain of self-driving cars. Mapless online path planning is particularly of practical appeal but poses a challenge for safely overtaking opponents due to the limited planning horizon. Accordingly, this paper introduces RaceMOP, a novel method for mapless online path planning designed for multi-agent racing of F1TENTH cars. Unlike classical planners that depend on predefined racing lines, RaceMOP operates without a map, relying solely on local observations to overtake other race cars at high speed. Our approach combines an artificial potential field method as a base policy with residual policy learning to introduce long-horizon planning capabilities. We advance the field by introducing a novel approach for policy fusion with the residual policy directly in probability space. Our experiments for twelve simulated racetracks validate that RaceMOP is capable of long-horizon decision-making with robust collision avoidance during over- taking maneuvers. RaceMOP demonstrates superior handling over existing mapless planners while generalizing to unknown racetracks, paving the way for further use of our method in robotics. We make the open-source code for RaceMOP available at http://github.com/raphajaner/racemop.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
The interactive decision-making in multi-agent autonomous racing offers insights valuable beyond the domain of self-driving cars. Mapless online path planning is particularly of practical appeal but poses a challenge for safely overtaking opponents due to the limited planning horizon. Accordingly, this paper introduces RaceMOP, a novel method for mapless online path planning designed for multi-agent racing of F1TENTH cars. Unlike classical planners that depend on predefined racing lines, RaceMOP operates without a map, relying solely on local observations to overtake other race cars at high speed. Our approach combines an artificial potential field method as a base policy with residual policy learning to introduce long-horizon planning capabilities. We advance the field by introducing a novel approach for policy fusion with the residual policy directly in probability space. Our experiments for twelve simulated racetracks validate that RaceMOP is capable of long-horizon decision-making with robust collision avoidance during over- taking maneuvers. RaceMOP demonstrates superior handling over existing mapless planners while generalizing to unknown racetracks, paving the way for further use of our method in robotics. We make the open-source code for RaceMOP available at http://github.com/raphajaner/racemop.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}