0%




Collaborative perception allows autonomous vehicles to use Vehicle-to-Everything (V2X) communication to share sensor information, enabling them to overcome individual limitations by seeing further and through occlusions. This capability is expected to dramatically improve the accuracy and safety of environmental perception. However, a major real-world challenge is “heterogeneity,” where vehicles from different manufacturers use varied sensors and perception models. This results in a “domain gap”—differences in the features of shared data—making effective information fusion difficult. Existing solutions have been impractical for real-world applications, as they require vehicles to undergo joint training on a large dataset beforehand, which is not feasible in dynamic traffic environments with new, unknown collaborators.
To address this challenge, our research introduces Progressive Heterogeneous Collaborative Perception (PHCP), a novel framework designed to solve this problem during inference (i.e., during actual driving) without any need for pre-training. PHCP formulates the problem as “few-shot unsupervised domain adaptation,” an approach where an ego vehicle dynamically aligns features by self-training with a small amount of unlabeled data from its collaborator. This allows for flexible and on-the-fly adaptation to any new vehicle it encounters.
The PHCP process consists of two stages. In Stage I, which lasts for the first few frames after a collaborative relationship is established, the agent vehicle transmits both its intermediate features and its own detection results, which serve as “pseudo labels.” The ego vehicle uses these pseudo labels to self-train a lightweight “adapter” that learns to translate the agent’s data into a format it can understand. Once the adapter is fine-tuned, Stage II begins. In this stage, the agent only needs to send its feature data, and the ego vehicle uses the trained adapter to transform and fuse the information, achieving efficient and highly accurate collaborative perception.
We conducted extensive experiments on the OPV2V, an open benchmark dataset for autonomous driving, to validate our framework’s effectiveness. The results demonstrate that PHCP consistently outperforms the direct fusion baseline method by approximately 30% in perception accuracy. Furthermore, our approach achieves performance comparable to state-of-the-art (SOTA) methods that were trained on the entire dataset, despite using only a minimal amount of unlabeled data. This proves that PHCP is a highly practical and effective solution for enabling robust collaborative perception in the diverse and unpredictable traffic scenarios of the real world.


autonomous driving machine learning

machine learning uav
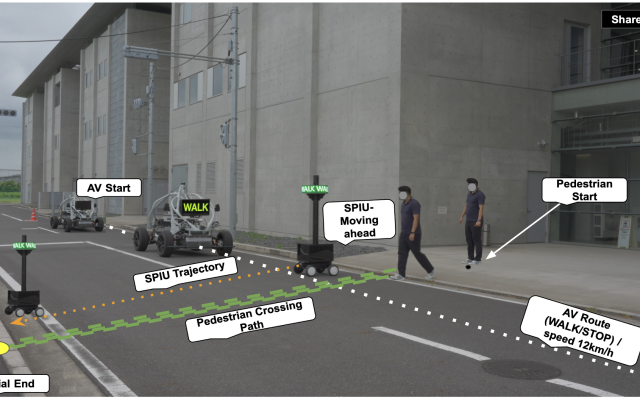
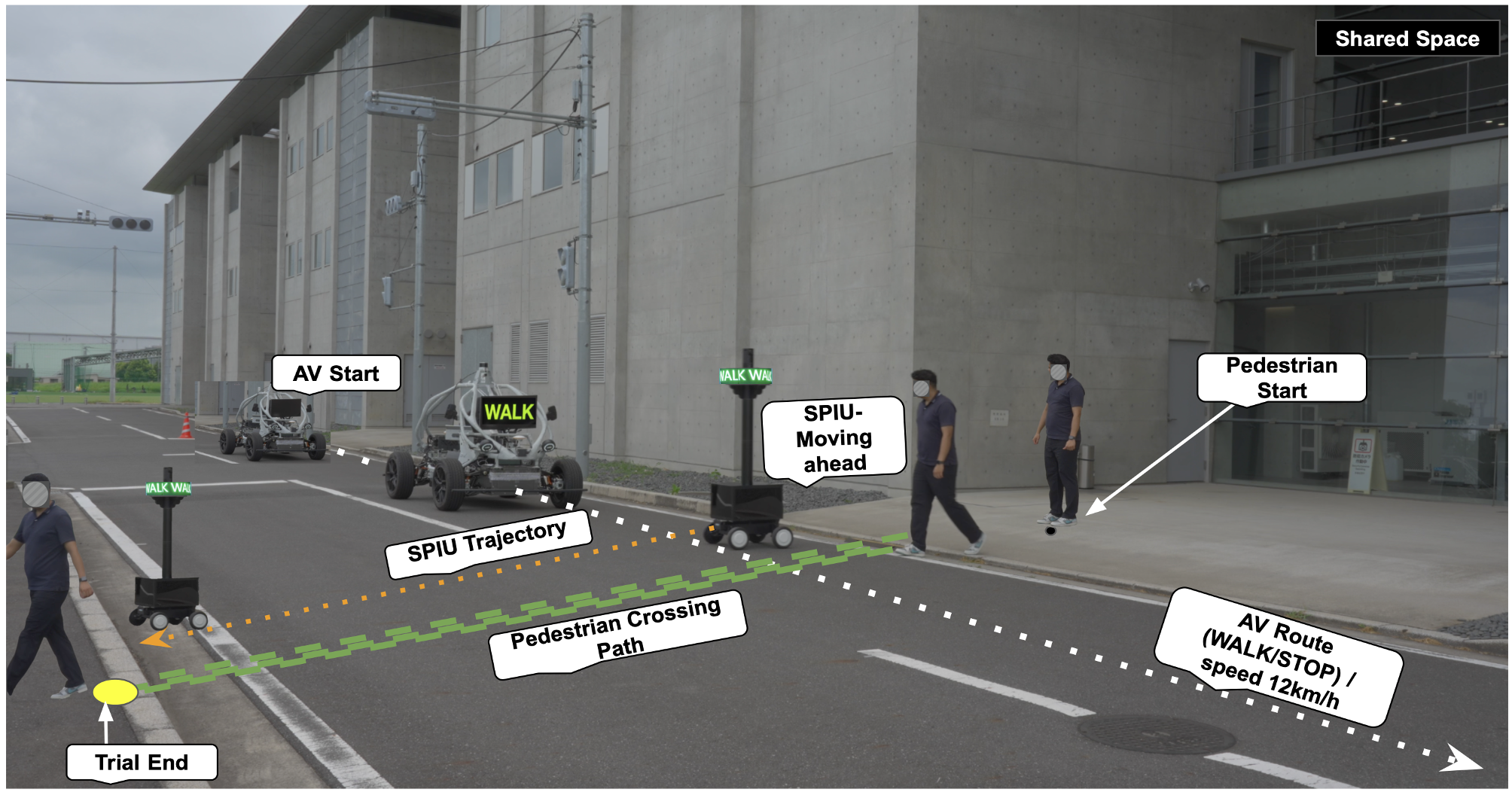
autonomous driving v2x
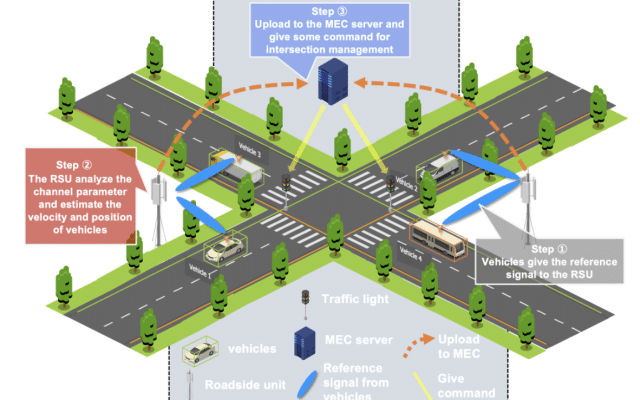
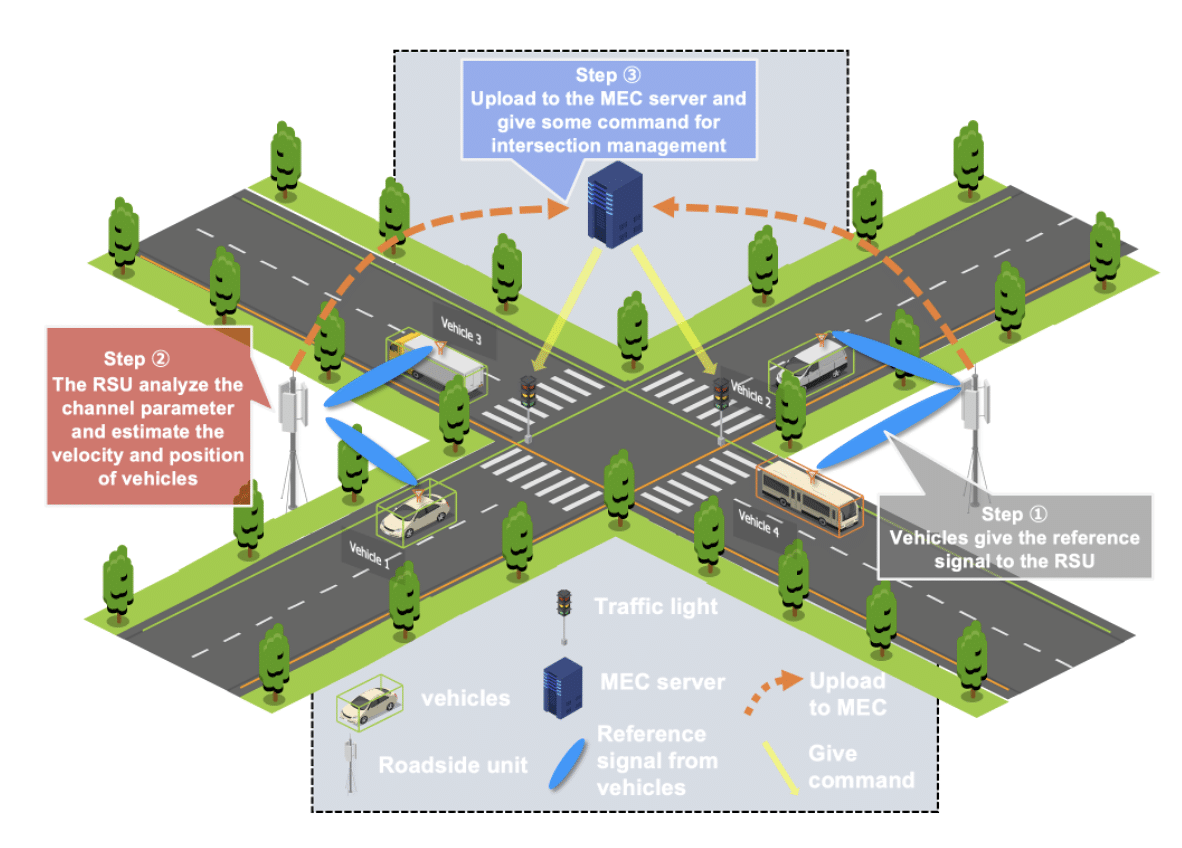
v2x

digital twins extended reality

digital twins uav

autonomous driving machine learning

machine learning v2x
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}