0%




A single autonomous vehicle is fundamentally limited in how completely it can understand a traffic scene. Onboard LiDAR and cameras are constrained by their physical viewpoint, so distant regions, blind corners, and occluded objects routinely fall outside any reliable sensing envelope. Vehicle-to-Everything (V2X) communication offers a way out of this single-agent bottleneck: when connected vehicles and roadside units share what they perceive, the resulting collaborative view can cover regions no individual sensor can reach. This project investigates how V2X cooperation can be applied to one of the most expressive forms of driving-scene understanding — 3D semantic occupancy prediction — and what is needed to make research in this direction reproducible and comparable.
Collaborative perception has so far been studied mainly for sparse outputs such as 3D bounding boxes and Bird’s-Eye-View segmentation, while 3D semantic occupancy — a dense voxel-level description of free space, occupied space, and per-voxel semantic class — has remained largely a single-vehicle problem. One important reason is the lack of a suitable benchmark: existing cooperative perception datasets are not designed around dense semantic voxel supervision, and existing occupancy datasets are not designed around multi-agent V2X scenarios. We address this gap by constructing a synthetic benchmark in which both sides are jointly considered from the start.
The benchmark is generated in the CARLA simulator with multiple time-synchronized agents — connected vehicles and roadside units — each equipped with realistic onboard sensors and a high-resolution semantic voxel sensor that produces dense ground truth around the agent. Scenes are designed to stress the cooperative setting: heavy occlusion in urban traffic, long-range perception requirements, and viewpoints that are clearly complementary across agents. Alongside the dataset, we define a unified evaluation protocol that allows ego-only and cooperative configurations to be compared on the same scenes under the same metrics, so that the contribution of V2X cooperation can be measured rather than assumed.
On top of this benchmark we provide reference baselines for collaborative 3D semantic occupancy prediction that perform inter-agent feature fusion before voxel-level decoding. These baselines demonstrate that cooperation yields clear, consistent gains over single-agent perception, especially in regions that are occluded or far from the ego vehicle, where single-agent occupancy prediction degrades the most. The dataset generation pipeline, ground-truth tools, and baseline implementations are released as open source so that future methods — including more efficient communication strategies, robustness studies, and learned cooperation policies — can be evaluated against a common, reproducible reference. The work is positioned as a foundation for the broader research agenda on cooperative perception in next-generation V2X-enabled autonomous driving.

autonomous driving machine learning

machine learning uav
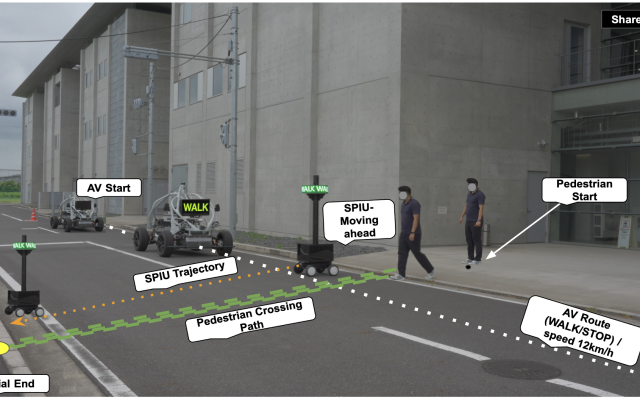
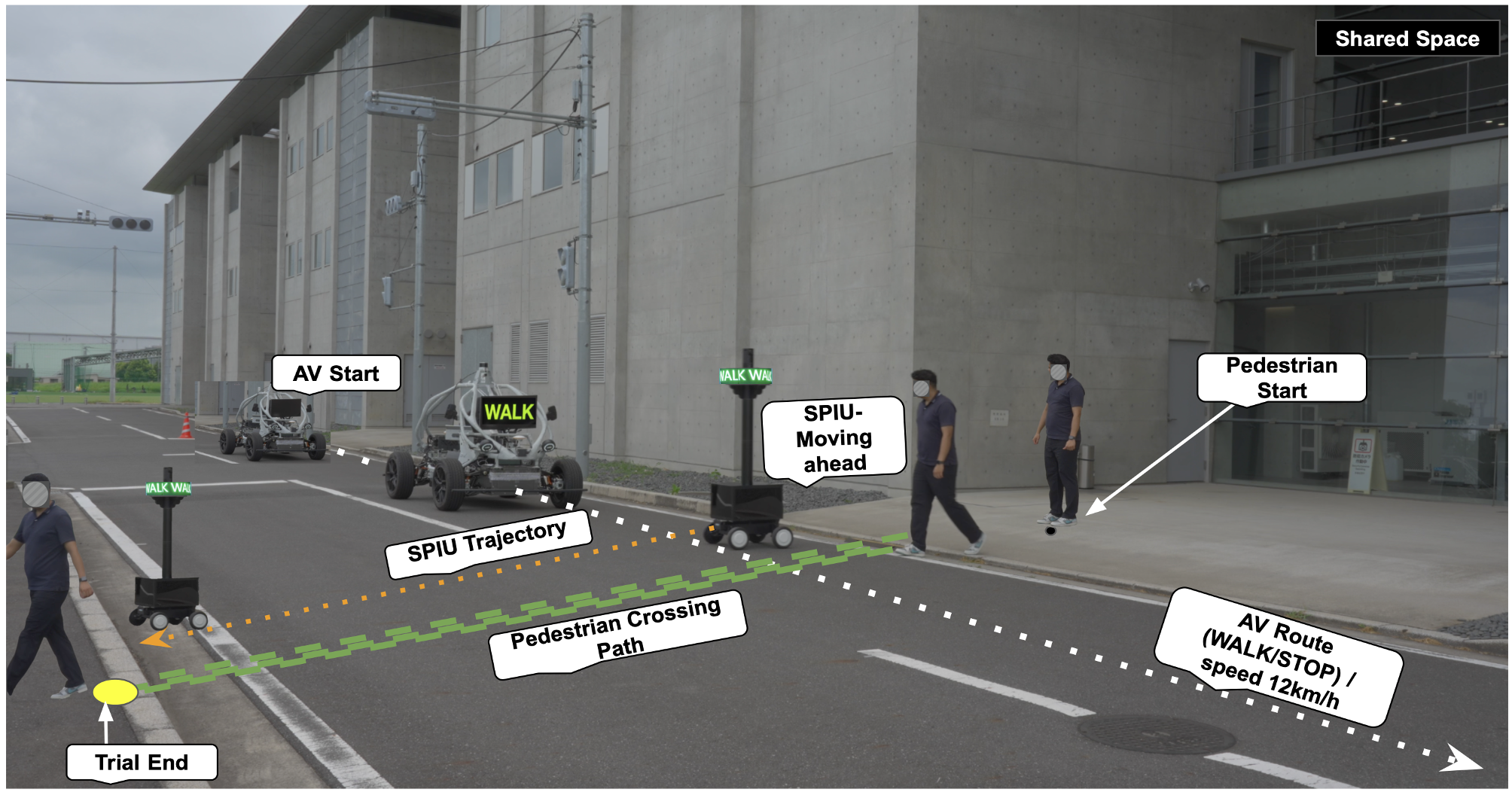
autonomous driving v2x
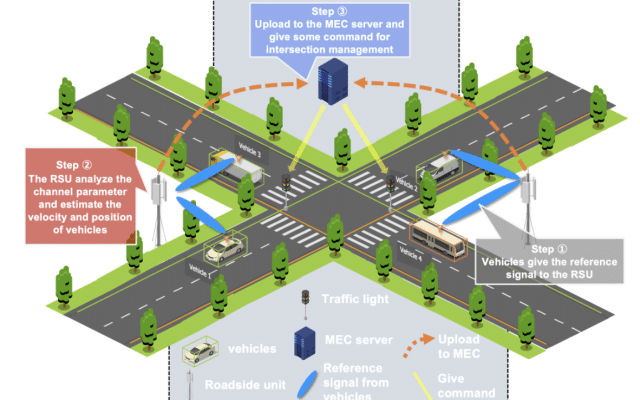
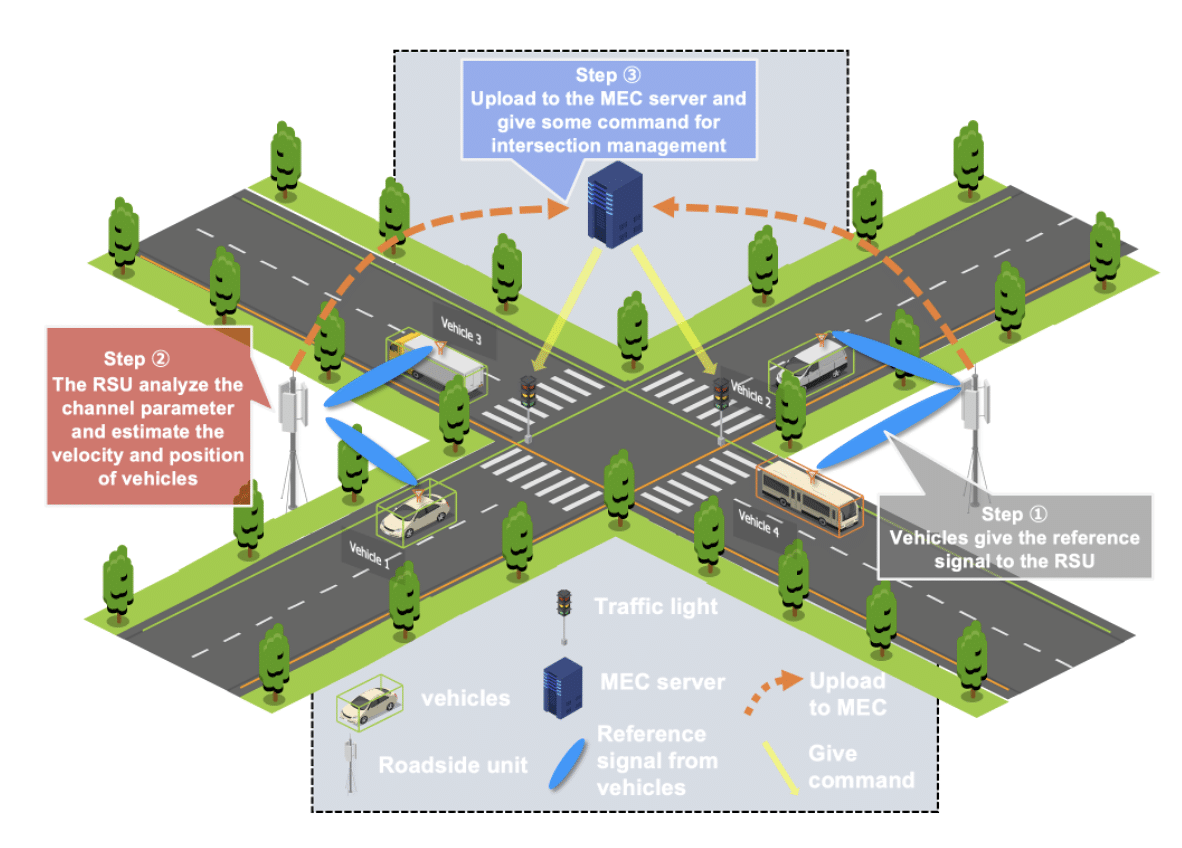
v2x

digital twins extended reality

digital twins uav

autonomous driving machine learning

machine learning v2x
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}