0%




単一の自動運転車が交通シーン全体を完全に理解できる範囲には、本質的な限界があります。車載LiDARやカメラは物理的な視点に縛られており、遠方領域・死角・遮蔽物の陰になる物体は、信頼できるセンシング範囲から日常的に外れてしまいます。Vehicle-to-Everything (V2X) 通信は、この単一エージェントのボトルネックから抜け出す手段を提供します。コネクテッド車両と路側機が知覚情報を共有することで、個々のセンサが到達できない領域までを協調的にカバーできます。本プロジェクトは、V2X協調を、走行シーン理解の中でも最も表現力の高い形式の一つである3Dセマンティック・オキュパンシ予測に適用する方法と、その方向の研究を再現性・比較可能性のあるものにするために何が必要かを調査するものです。
協調知覚はこれまで、主に3Dバウンディングボックス検出やBEV (Bird’s-Eye-View) セグメンテーションといった疎な出力を対象に研究されてきました。一方、自由空間と占有空間、そしてボクセル単位のセマンティッククラスを密に記述する3Dセマンティック・オキュパンシは、これまでほぼ単一車両の問題として扱われてきました。理由のひとつは、適切なベンチマークが存在しないことです。既存の協調知覚データセットは密なボクセル教師信号を念頭に設計されておらず、既存のオキュパンシ予測データセットはマルチエージェントなV2X環境を念頭に設計されていません。本プロジェクトは、この両側面を最初から同時に考慮した合成ベンチマークを構築することでこのギャップを埋めます。
ベンチマークは CARLA シミュレータ 上で、時刻同期された複数のエージェント(コネクテッド車両および路側機)を用いて生成します。各エージェントには、現実的な車載センサに加えて、エージェント周辺の密な正解データを生成する高解像度セマンティック・ボクセルセンサが搭載されています。シーンは協調設定が効くケースを意図的に強調するよう設計されており、市街地交通における強いオクルージョン、遠方領域への要求、エージェント間で明らかに相補的な視点などが含まれます。データセットに加えて、ego-only と cooperative の構成を同じシーン・同じ評価指標で比較できる統一的な評価プロトコルを定義し、「V2X協調がどの程度寄与するか」が仮定ではなく計測対象になるようにしています。
このベンチマーク上で、エージェント間で特徴量を融合してからボクセル単位のデコードを行う、協調3Dセマンティック・オキュパンシ予測のためのリファレンス手法を提供します。ベースラインは、単一エージェント手法に対して協調が一貫した精度向上をもたらすこと、特に単一車両の精度が最も劣化する遮蔽領域・遠方領域でその差が顕著であることを示しています。データセット生成パイプライン、正解データツール、ベースライン実装はオープンソースとして公開予定であり、より効率的な通信戦略、ロバスト性評価、学習された協調戦略といった将来手法を、共通かつ再現可能な基準で評価できるようにします。本研究は、次世代V2X協調自動運転における協調知覚研究の土台として位置付けられます。

autonomous driving machine learning

machine learning uav
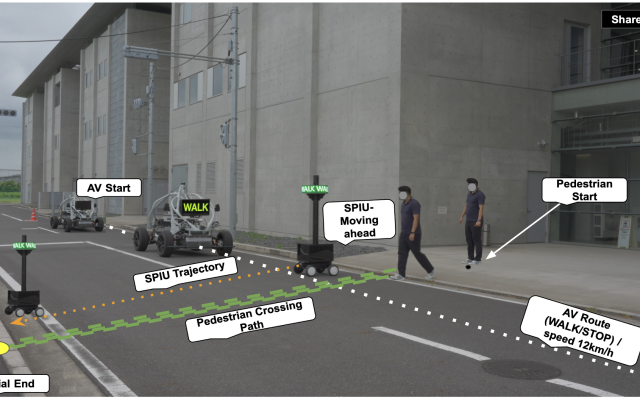
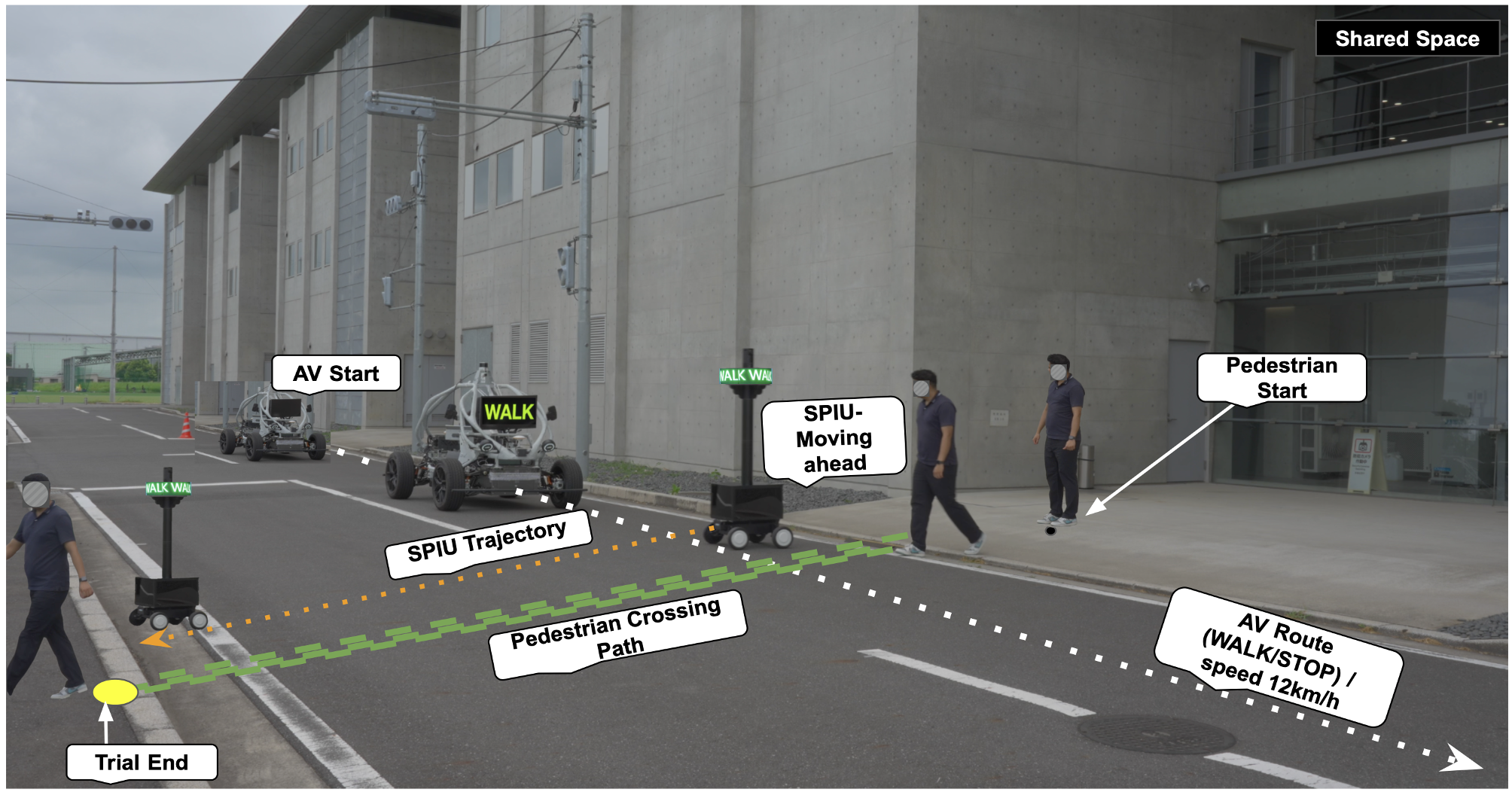
autonomous driving v2x

digital twins extended reality

digital twins uav

autonomous driving machine learning

machine learning v2x
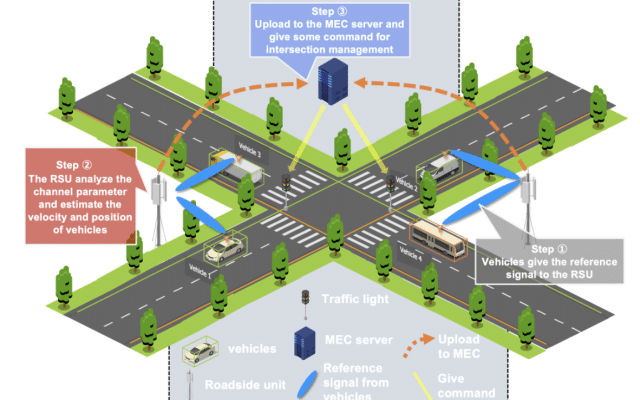
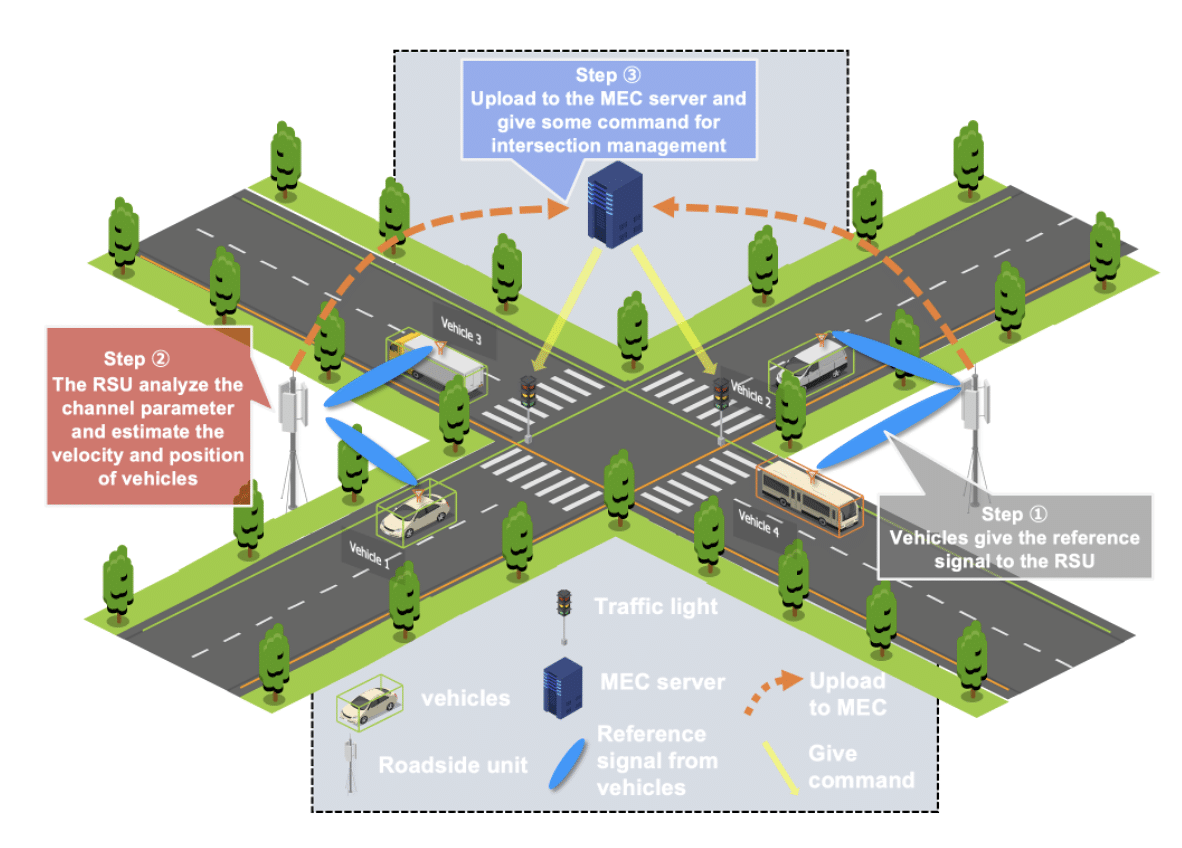
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}