0%






UAV(ドローン)とAMR(地上ロボット)は、互いに補完的な自律プラットフォームである。UAVは到達困難な領域へのアクセス、人命リスクの低減、迅速な展開といった利点を備える一方、バッテリー、ペイロード、気象、規制といった制約に直面する。AMRは工場内において高い稼働持続性、ペイロード、柔軟性を提供するが、垂直方向への到達範囲、地形上の制約、システム統合の手間といった代償を伴う。両者はいずれも6Gネットワークにおける第一級のエンドポイントとなる。
本研究では、新規の強化学習(RL)アルゴリズムを核とするエンドツーエンドの計画フレームワークを提案するとともに、CARLA/AirSimによるシミュレーションパイプラインおよび小規模な物理テストベッドを構築する。本フレームワークは閉ループ評価を対象とし、計画器の出力がエージェントを駆動して逐次的な誤差が累積する状況を扱う。設計は次の三つの性質に基づいて導かれる。すなわち、サイトやタスクを跨いだ転移を可能とする汎化性、学習時および推論時の計算効率、ならびに認識・ダイナミクス・目的関数を差し替え可能とするカスタマイズ性である。
四つのアルゴリズムはマルチエージェントRLという共通の骨格を持ちつつ、それぞれ異なる軸において特化されている。UA-MARL(Uncertainty-Aware Multi-Agent RL)はサンプル効率の向上を目的とする。ITDQN(Imitation-based Triple Deep Q-Learning)は探索と活用のバランスを取ることを意図して設計されている。FM-EAC(Feature Model-based Enhanced Actor-Critic)は学習効率と汎化性の改善を目指す。そして、EIA-SEC(Elite Imitation Actor-Shared Ensemble Critic)は学習効率とカスタマイズ性の向上を目標とする。
アルゴリズム開発は二つのシミュレータによって支えられる。一つはCARLAであり、近代的なレンダリングパイプライン、事前構築された都市マップ、TCP経由で遠隔制御可能なカメラ/LiDARなどのシミュレートセンサを備えたオープンソースの自動運転シミュレータで、AMR側の実験対象として自然な選択肢となる。もう一つはAirSimであり、Unreal Engineを基盤とし、プラットフォーム非依存のAPIを提供することからUAV向けの深層学習およびRL研究で広く用いられている。物理テストベッドは、DJI Tello UAV 4機、Raspberry-Piコントローラ 4台、地上AMR 4台で構成され、今後さらにカメラ、IMU、LiDARの追加が計画されている。このテストベッドは、オペレータの介入が方策更新へとフィードバックされるヒューマン・イン・ザ・ループ実験を支援することを念頭に設計されている。

autonomous driving machine learning

machine learning uav
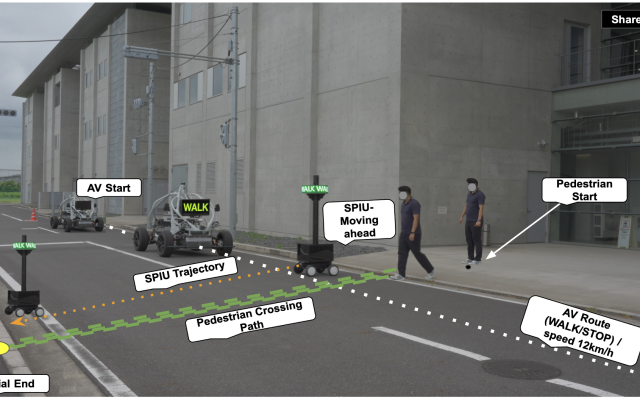
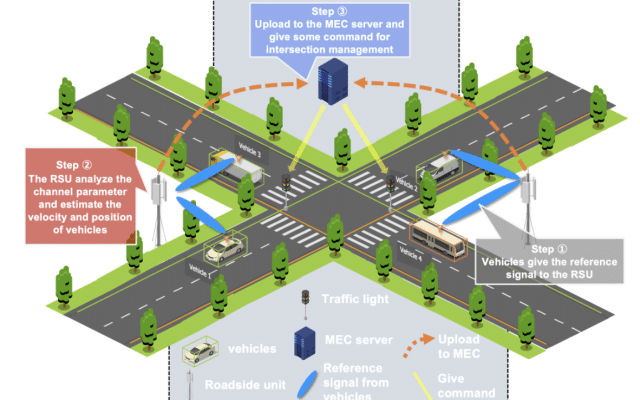
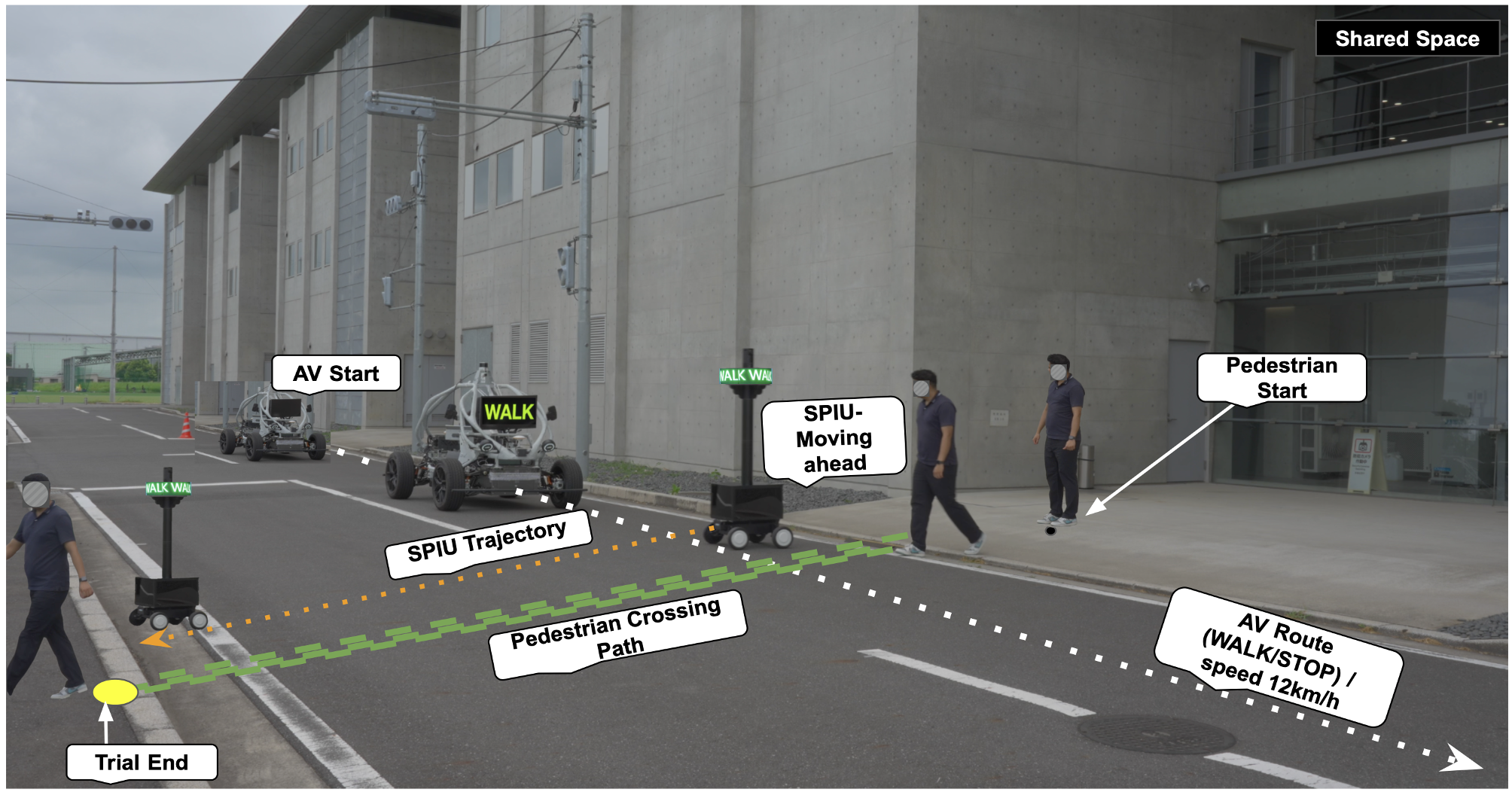
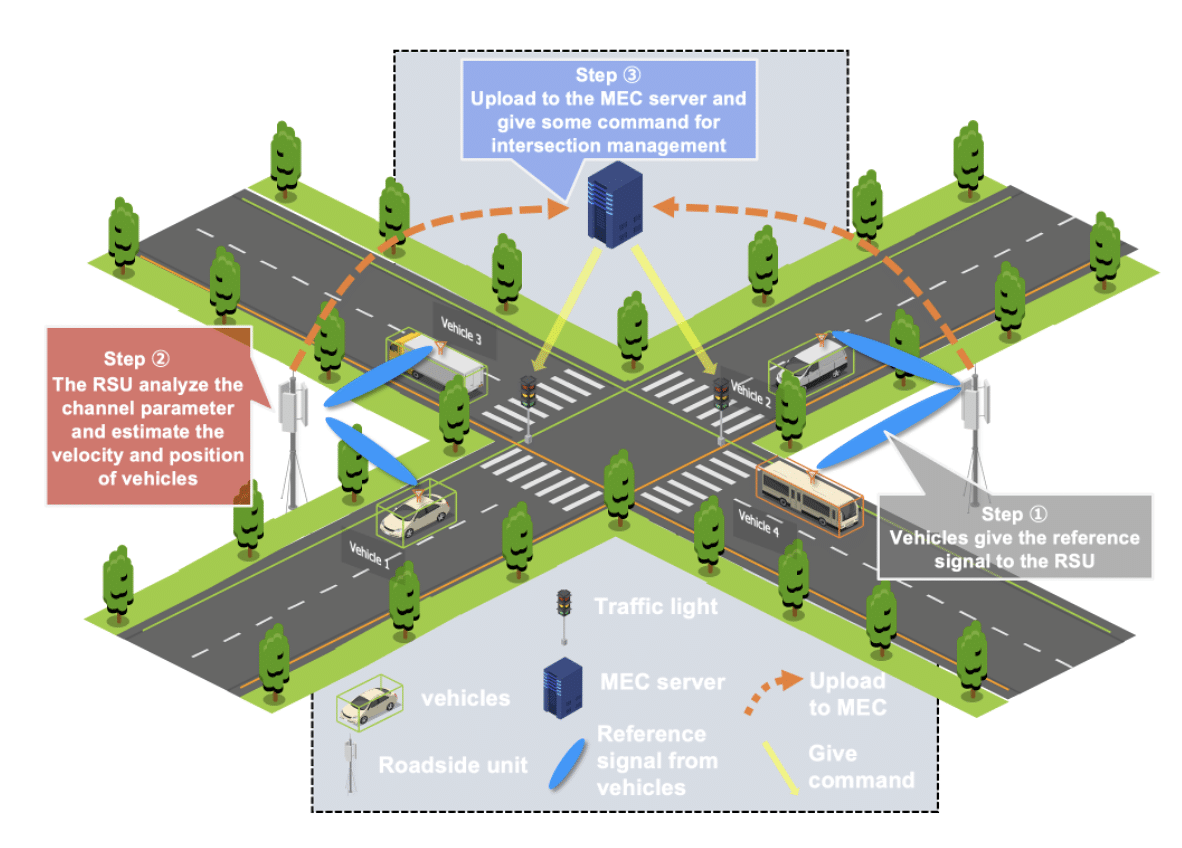
autonomous driving v2x

digital twins extended reality

digital twins uav

autonomous driving machine learning

machine learning v2x
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}