0%




自動運転技術が進化する中で、単にルールに従うだけでなく、人間のようにスムーズで安全、かつ快適な運転を実現することが次の大きな課題となっています。そこで本研究プロジェクトでは、近年のAI技術の中核である大規模言語モデル(LLM)を活用し、人間の持つ繊細な運転の「好み」(例えば、適切な車間距離の維持やスムーズな加減速など)を自動運転モデルに組み込む「PrefDrive」フレームワークを開発しました 。これにより、交通法規の遵守といった基本的な要求から、より人間らしい運転挙動まで、幅広い要求に応えられるシステムの実現を目指します 。
PrefDriveの核心は、「直接的選好最適化(DPO)」という選好学習の手法を自動運転分野で先駆けて導入した点にあります 。これは、特定の交通状況において「望ましい運転操作(chosen)」と「望ましくない運転操作(rejected)」のペアをモデルに提示し、その比較から人間にとっての最適解を学習させるアプローチです 。この研究のために、74,040シーケンスにも及ぶ独自の運転選好データセットを構築し、公開しました 。また、LoRAや4ビット量子化といったメモリ効率化技術を駆使することで、研究室レベルの一般的なGPUでも高度なLLMのファインチューニングを可能にし、研究のアクセス性を高めています 。
しかし、実際の運転における意思決定は、単純な二者択一ではありません。一つの正しい操作に対し、危険性の度合いが異なる複数の誤った選択肢が存在します 。この複雑な判断のニュアンスを捉えるため、我々はプロジェクトをさらに進化させ、「Multi-PrefDrive」を開発しました 。この新フレームワークでは、一つの「望ましい操作」に対して、「攻撃的すぎる」「不注意」「過度に慎重」といった複数の「望ましくない操作」をセットで学習させます 。これにより、モデルは多様なエラーの中から最適な行動をより精密に見分ける能力を獲得します。
Multi-PrefDriveでは、複数の選択肢を扱うためにPlackett-Luceモデルという高度な選好モデルを実装しました 。CARLAシミュレータを用いた実験では、このアプローチが従来のDPOを上回り、特に安全性において劇的な性能向上を達成することを示しました。具体的には、インフラとの衝突を83.6%削減し、特定の環境下では信号無視を完全にゼロに抑えることに成功しました 。この成果は、人間の複雑な判断基準をAIに学習させることが、より安全で信頼性の高い自動運転の実現に不可欠であることを示しています。

autonomous driving machine learning

machine learning uav
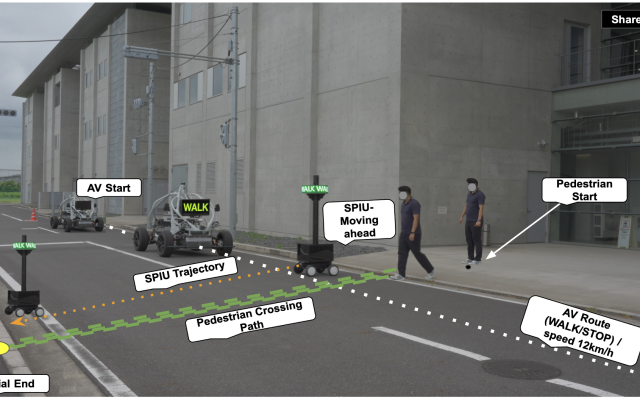
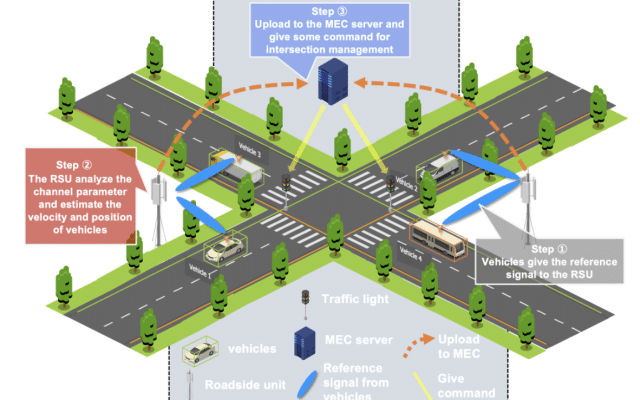
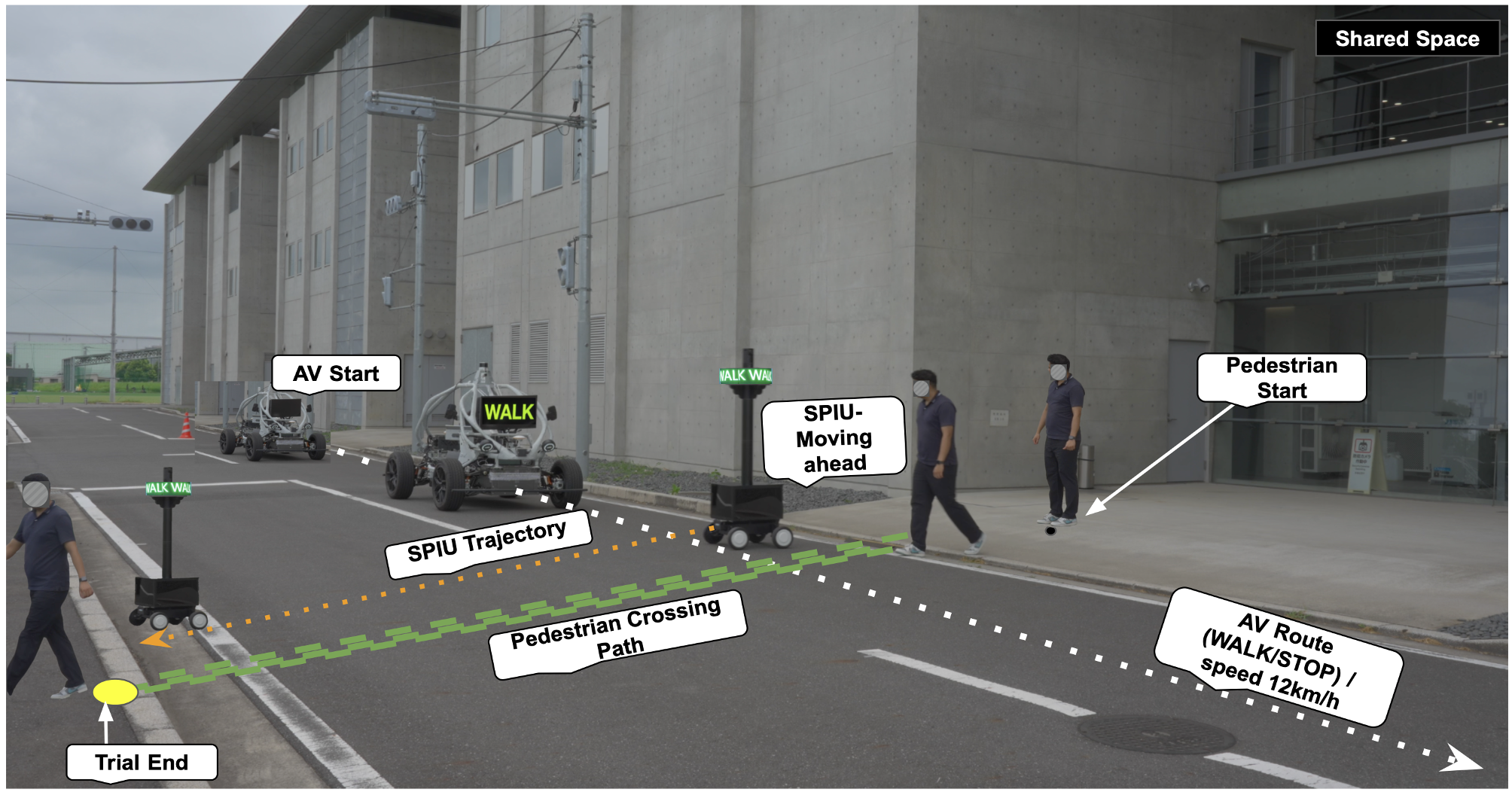
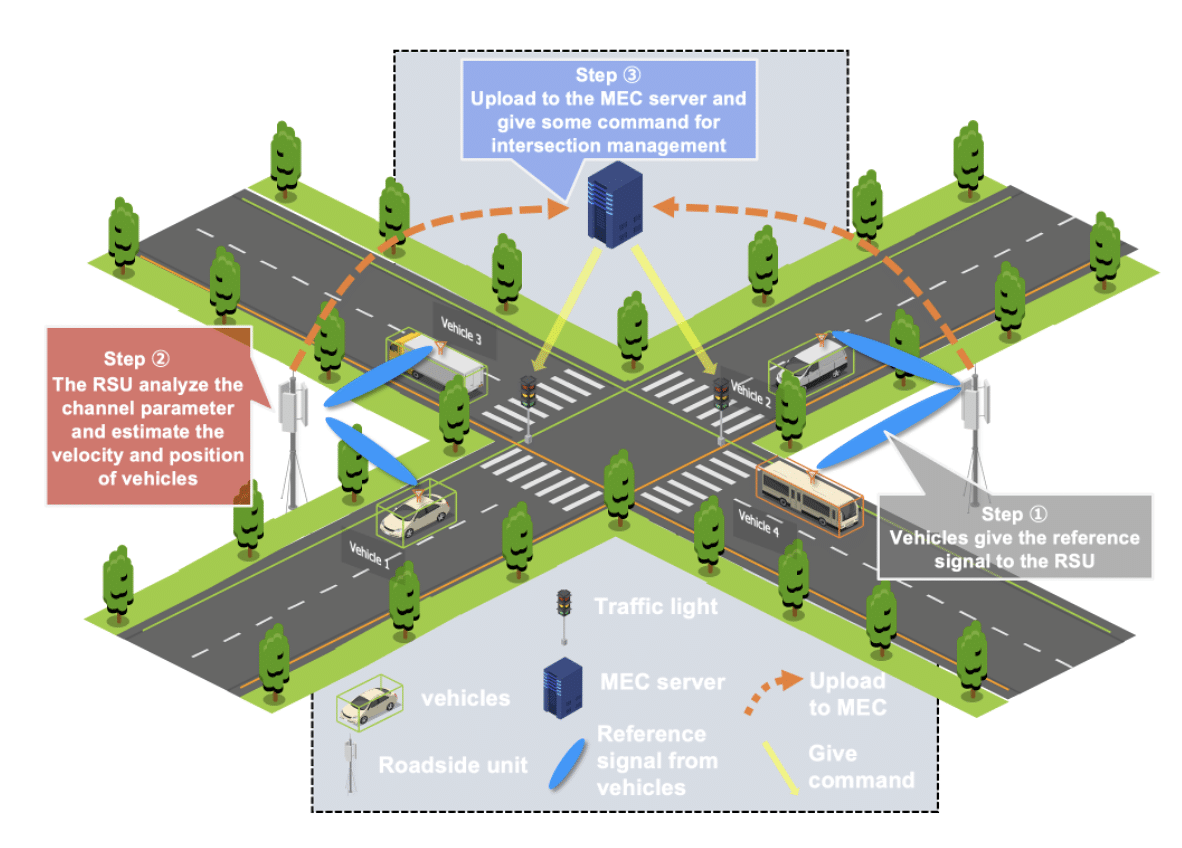
autonomous driving v2x

digital twins extended reality

digital twins uav

autonomous driving machine learning

machine learning v2x
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}