0%

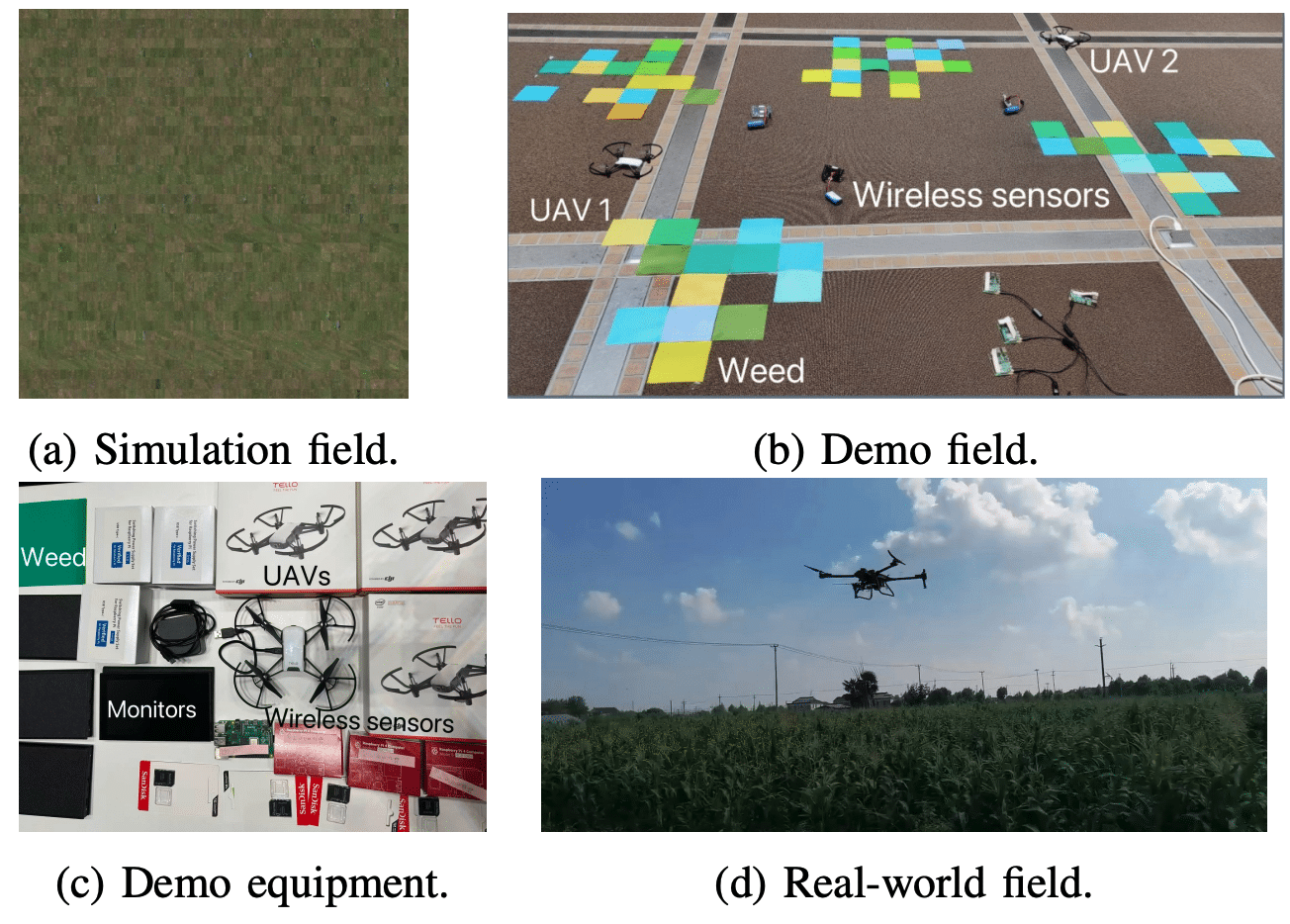





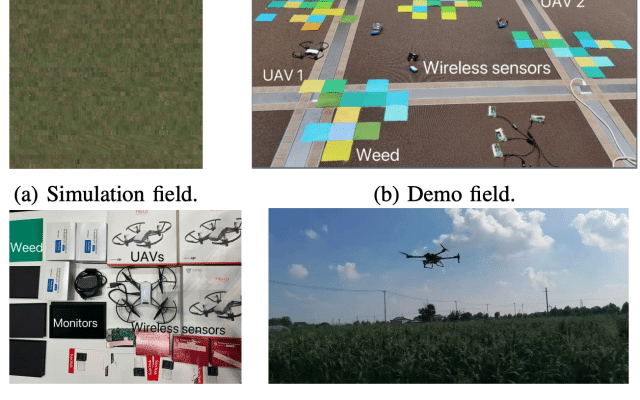
UAVs (drones) and AMRs (ground robots) are complementary autonomy platforms. UAVs offer access to hard-to-reach areas, reduced risk to human life, and rapid deployment, but face battery, payload, weather, and regulatory limits. AMRs deliver high endurance, payload, and flexibility on the factory floor at the cost of vertical reach, terrain limits, and integration effort. Both will be first-class endpoints in 6G networks.
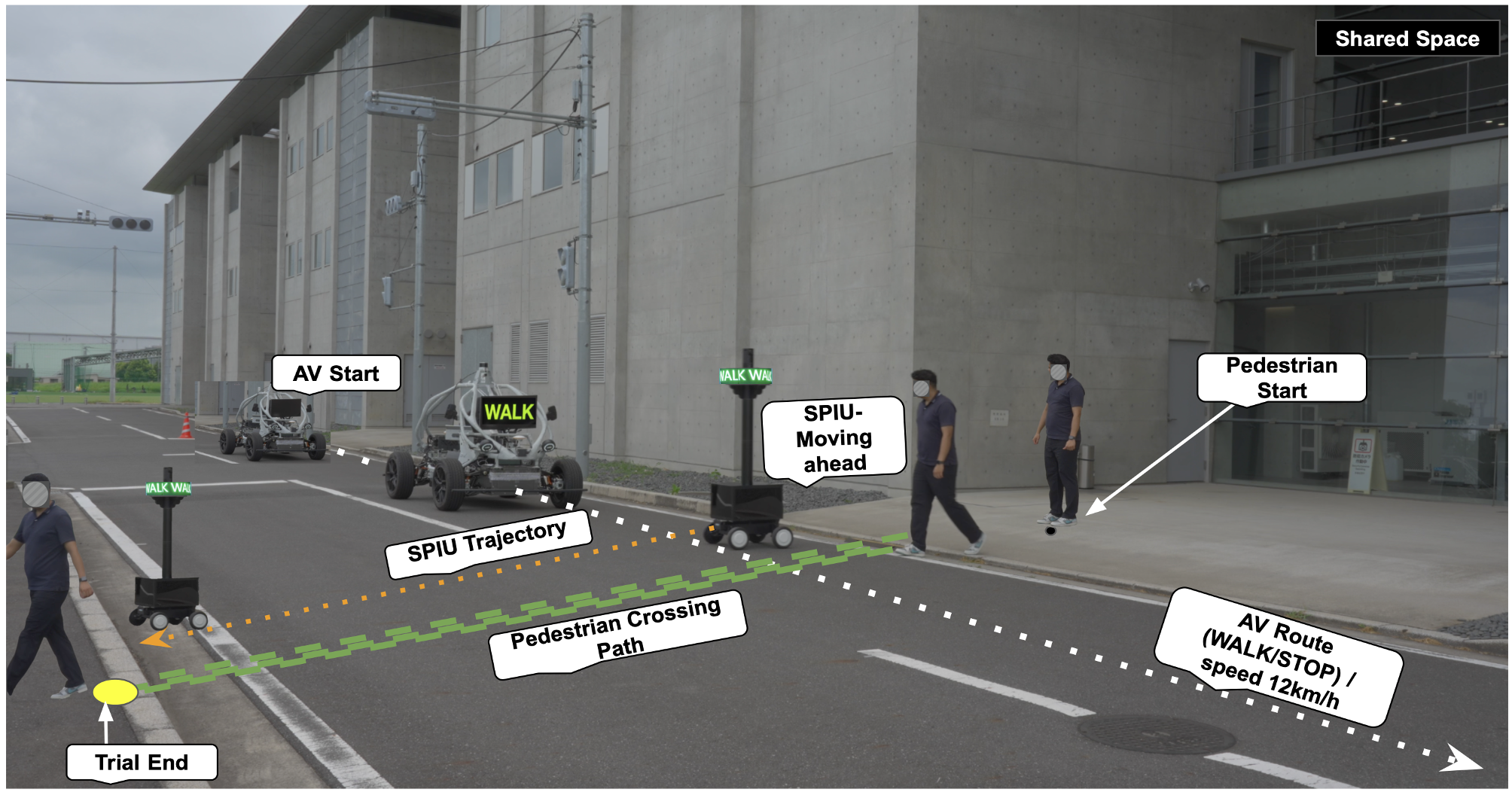
This research presents an end-to-end planning framework with novel reinforcement-learning (RL) algorithms, together with a CARLA/AirSim simulation pipeline and a small physical testbed. The framework targets closed-loop evaluation, where planner outputs drive the agent and successive errors compound, and is guided by three properties: generality (transfer across sites and tasks), efficiency (sample- and inference-time), and customizability (swappable perception, dynamics, and objectives).
Four algorithms share a multi-agent RL skeleton and specialize it along different axes. UA-MARL (Uncertainty-Aware Multi-Agent RL) aims to increase sample efficiency. ITDQN (Imitation-based Triple Deep Q-Learning) is designed for balancing exploration and exploitation. FM-EAC (Feature Model-based Enhanced Actor-Critic) targets improving training efficiency and generalizability. Finally, EIA-SEC (Elite Imitation Actor-Shared Ensemble Critic) has the goal of improving training efficiency and customizability.
Two simulators support algorithm development: CARLA, an open-source autonomous-driving simulator with a modern rendering pipeline, pre-made urban maps, and simulated camera/LiDAR sensors controlled remotely over TCP — the natural target for AMR-side experiments; and AirSim, an Unreal-Engine-based simulator with platform-independent APIs widely used for UAV deep-learning and RL research. The physical testbed comprises four DJI Tello UAVs, four Raspberry-Pi controllers, and four ground AMRs, with additional cameras, IMUs, and LiDAR planned. The setup is designed to support human-in-the-loop experimentation in which operator interventions feed back into policy updates.
uav
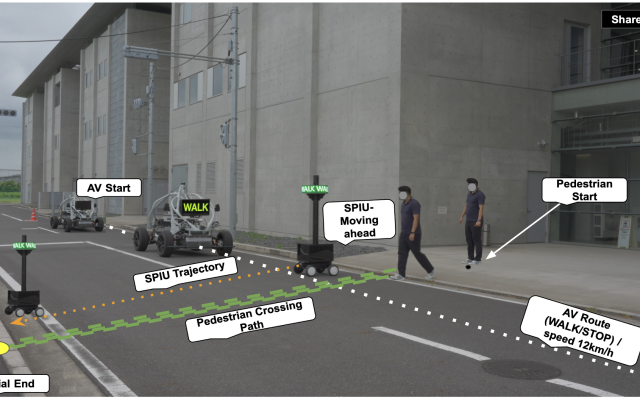
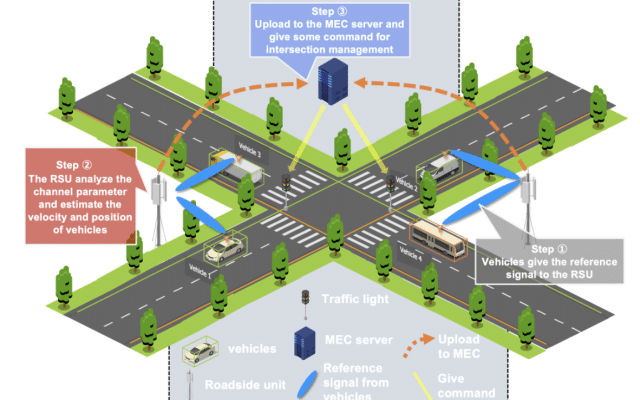
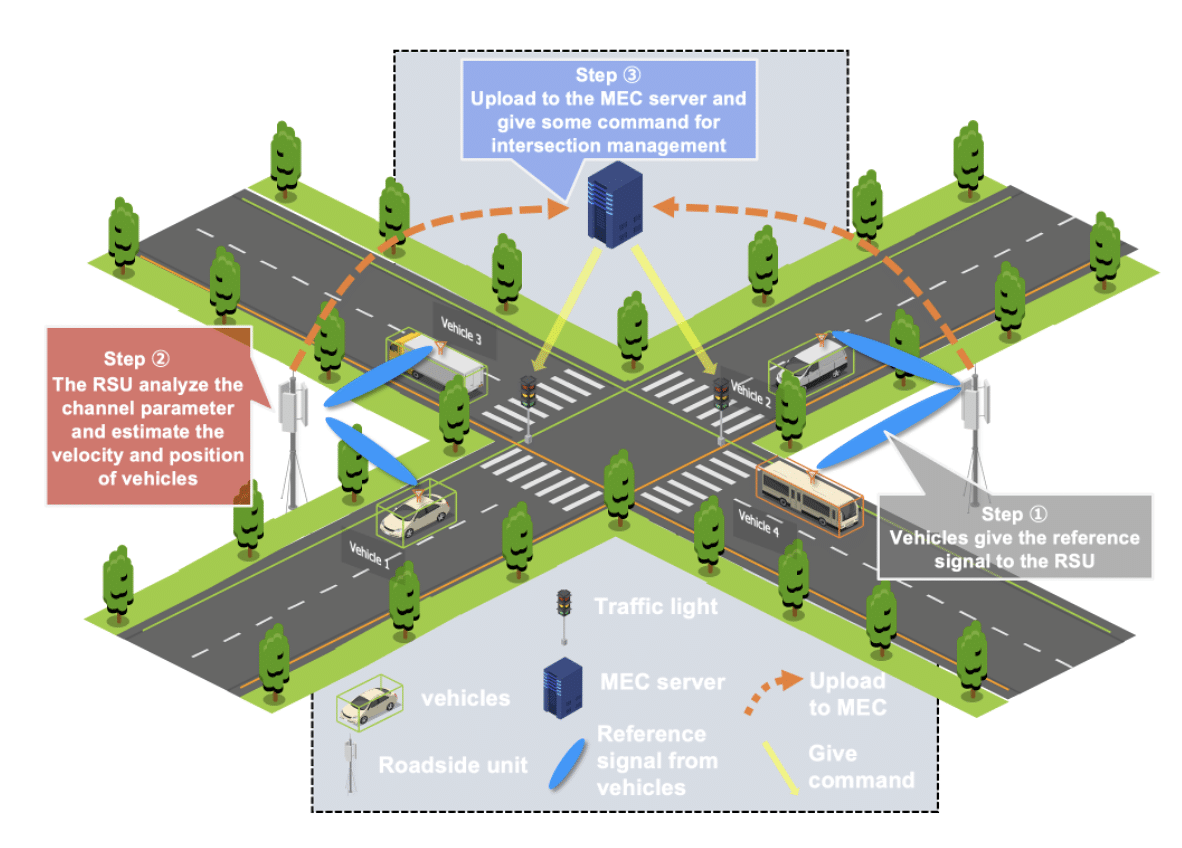
autonomous driving v2x
v2x

digital twins extended reality

digital twins

autonomous driving machine learning

machine learning v2x

autonomous driving v2x
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}